
Last November this post by Alex Woodie from Datanami made quite an impression on the Big Data community.
Central to this post was this diagram taken from Google Trends showing Spark in blue climbing dramatically and overtaking Hadoop in red. Even if you didn’t read the article, you got the gist of it by looking at the curves. Such is the power of good data visualization!
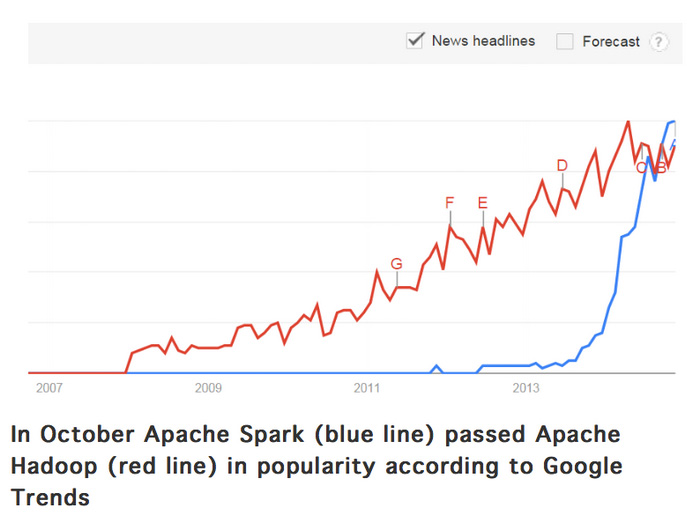
And so the rumor spread like wildfire: it was such a good story, we all wanted to believe in it.
I told the story too during the training sessions I delivered until one day, a bright participant with a curious mind asked if we could check the facts directly using Google Trends.
¡No problemo! Let’s check the facts!
I entered Hadoop as the first search term in Google Trends and Spark as the second one. Then Google reminded me that Spark could be many things: a spark plug, a car, some kind of transmitter, a fictional character. Ok, I got it. I needed to be more specific, so I entered ‘Apache Spark’, hit return and obtained the following result.
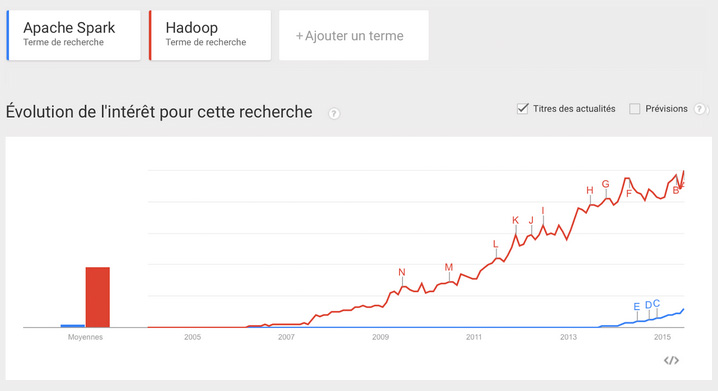
This is, ahem, much less impressive!
It’s starting to ramp up like Hadoop six years ago but it is nowhere near the tsunami depicted by Datanami.
For me this is the correct set of search terms since none of them are ambiguous. There are no characters, cars or things called Hadoop besides Hadoop the software. If I google Hadoop, all the links returned will be relevant. There is no need to be more specific.
But just for kicks, let’s compare ‘Apache Hadoop’ and ‘Apache Spark’.
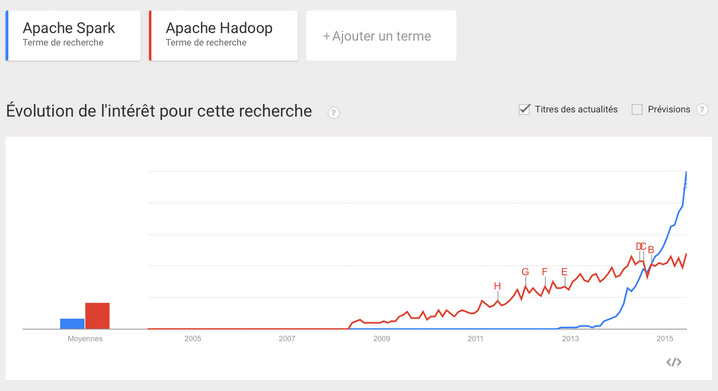
Bingo!
This is how they managed to get this spectacular diagram: by being unnecessarily specific for the Hadoop search term.
This is so incredibly stimulating: I want to be creative too.
Let’s compare ‘Apache Spark’ and ‘Apache Hadoop Open Source Software’.
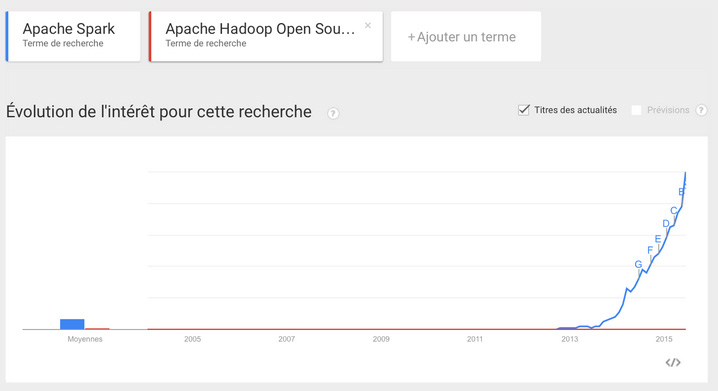
Voila! I made Hadoop completely disappear!
Can I make Spark disappear too?
Of course! All I need is to compare ‘Apache Spark framework’ and Hadoop’.
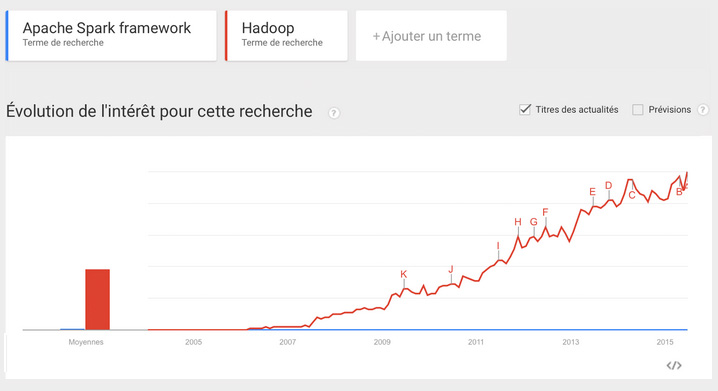
I am unstoppable! Can I make them both disappear?
Mais oui ! Although with some help from a third party.
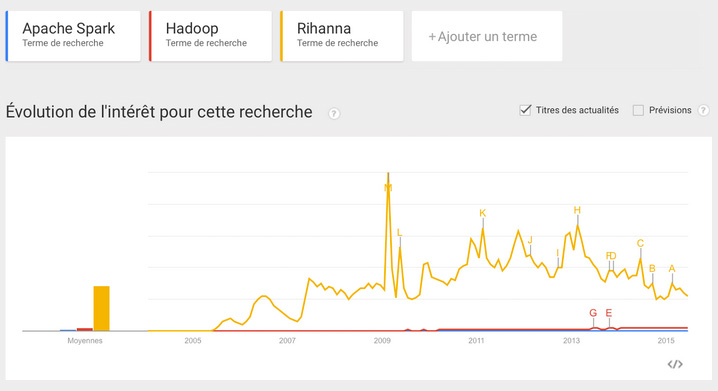
OK enough silliness! I think there are three lessons that can be drawn from these experiments.
I have included my search terms in my screen shots so that you can reproduce my searches at the cost of showing you some French. Reproducibility is a key ingredient in data science. It’s ironic that a news portal about Big Data should present data in such a misleading way.
Judging from Google Trends, Spark is not taking over Hadoop yet but it is taking off. So it definitely is a technology worth monitoring in the new and fast paced ecosystem of Big Data.
The idea that the popularity of Hadoop has peaked is not validated by the data provided by Google: it is in fact still growing.
This article was originally posted on the Neoxia blog site: http://blog.neoxia.com/hadoop-vs-spark-a-tale-of-data-manipulation/.
 Follow
Follow Forward
Forward