

As part of my job in Neoxia, I deliver two Big Data training courses for Learning Tree in France: One is an introduction to the fundamentals and the other is on developing Hadoop-based solutions in Java. The first one has been quite successful lately, so I get the privilege of revealing to my students the magic of counting words with Hadoop on a weekly basis.
To introduce this highlight of the training session, we first consider the traditional approach a developer would take to counting the words in a set of text files.
It goes something like this in pseudo Java:
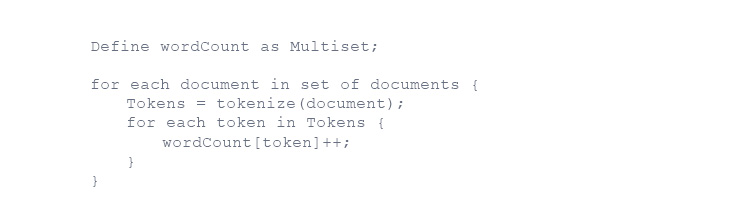
Then we take a few minutes to discuss the pros and cons of this approach.
Eventually we all agree that since it is sequential, it cannot scale and therefore that it’s incredibly naive.
And until recently I forgot to add by today’s standards.
But now I have a brand new perspective on this snippet of code: I no longer consider it as the result of an uninspired effort from a Java beginner but as the heritage from the golden standard for Cobol batch jobs from the 80’s: for each customer perform some kind of processing.
Those jobs are still out there running a significant size of the world’s business.
Like word counting, could they too benefit from a map reduce approach?
Let’s take a monthly billing job for instance.
First let’s examine how we could technically use Hadoop do perform this job. Billing a customer is the result of applying a common pricing policy to customer’s specific data. So provided we manage to fit the pricing policy in a distributed cache, the billing could take the form of a map-only job like the one below:
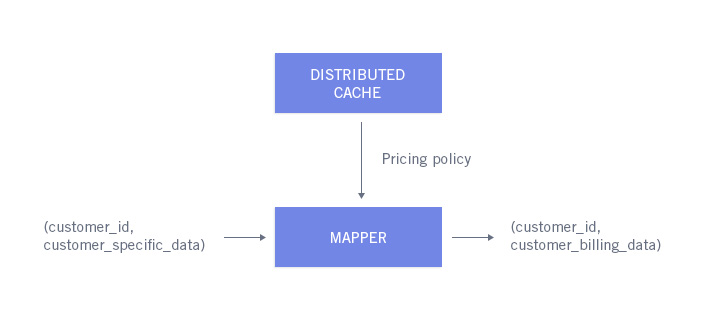
What would the potential business case be like if we used Hadoop to perform billing ?
Is it a good idea to bill faster ? Ask your favorite CFO and prepare to be amazed: the guy can actually smile. Some of these legacy jobs have grown so large that they span several days thus losing precious days’ worth of cash flow.
Is it worth the trouble to port legacy billing code to Java-based Hadoop code? It could be. The documentation of 30 year old code is likely to be in poor shape. Being able to document the new code with unit tests would give the company confidence in its ability to change the pricing policy or launch new products with unprecedented speed of execution. Reducing the footprint of legacy hardware and software in your information system is also a step in the right direction. It is the only way to eat an elephant: one bite at a time.
There are many misconceptions around Big Data.
One of which is that there is a threshold of data volume below which you can continue to rely on traditional solutions and above which you need to use the new generation of tools. Framing the problem in those terms often leads to dismiss Big Data since most companies do not have use cases involving petabytes of data. And maybe that is the implicit request underneath the question: can I continue to do IT in my tried and tested way please ?
This approach misses the point: the new tools that are associated with Big Data bring to the table solutions to problems that were not well addressed by the former generation of tools. Solution architecture decisions should not be based on a simple rule like this one:

Instead those decisions should be based on a more relevant set of questions such as:
• can this job benefit from parallel processing ?
• what is the most efficient way to store this data? tables ? documents ? graphs ? key-value pairs ?
• and by the way, how badly does this data really need to be stored on premises ?
There are more use cases for the new generation of tools than just taking over when the volume of data makes them mandatory.
What if Hadoop became the new golden standard for batch processing ?
This article was originally posted on the Neoxia blog site: http://blog.neoxia.com/using-hadoop-to-perform-classic-batch-jobs/.